YANAI Lab.
電気通信大学 総合情報学科/大学院 総合情報学専攻 メディア情報学コース 柳井研究室
| |
YANAI Lab.電気通信大学 総合情報学科/大学院 総合情報学専攻 メディア情報学コース 柳井研究室 |
| 電気通信大学 > 情報工学科 > コンピュータ学講座 > 柳井研究室 > 研究紹介 |
質感語に対応する画像の認識可能性の評価下田 和 Date: 平成 27 年 2 月 17 日
1 はじめにこれまで,一般的な物体画像,食事画像,素材画像の認識など,様々な物体認識の研究が行われてきた. 本研究では,物体の質感に着目,最新の画像認識手法を用いて,質感を表現する言葉に対応する画像の認識可能性の評価を行う. 質感は物体の形に依存しないので認識が難しいことが予測されるが,近年,画像認識の精度は向上しており,画像から物体の質感を認識できる可能性がある.本研究では,質感を表現する語としてオノマトペを用いた. オノマトペに対応するWeb画像を収集し,認識可能性を評価する.
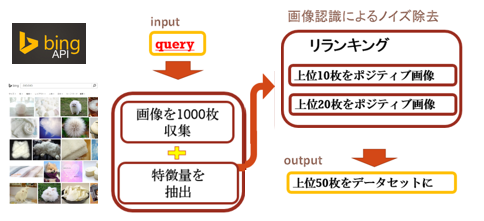
2 関連研究関連研究としては,Cimpoi[1]らなどの素材画像認識の研究がある. LiuらによるFlickr Material Database(FMD)[2]の認識が代表的である. FMDは繊維, ガラス,金属などの10種類の素材カテゴリからなるデータセットで,これらの画像を分類する研究が盛んにされてきた.3 概要本研究では,Web画像におけるノイズ画像を自動で除去し,オノマトペに対応する画像を収集した. 図1に画像を収集する際の流れを示した.
4 手法の詳細
1 画像の収集Bing Image search APIを用いてWeb画像の収集を行った. 各クエリについてAPIの上限の1000枚まで画像を収集した.
2 ノイズ画像の除去WebAPIで収集した画像には,上位の画像であってもノイズ画像が含まれてしまうことがある. そこで,画像認識によるリランキングによりノイズ画像を除去する.本研究では,擬似ポジティブ画像として検索結果上位の画像,ネガティブサンプルにランダム画像を用いてSVMを学習する. SVMを各画像に適用した際に得られる出力値の大小で,画像にランキングを与え,リランキングを行う.
3 認識可能性の評価正解画像を50 枚,不正解画像を5000 枚として,これを学習しSVMモデルを作る. このSVMモデルを使って,5050枚の画像を分離し,この分離度合いで,認識可能性を評価した. 具体的な精度,数値は,平均適合率を用いた.4 画像特徴量画像特徴量の表現はImproved Fisher Vector と Deep Convolutional Neural Network (DCNN) を用い,識別器には線形SVMを用いる.1 Improved Fisher Vector(IFV)[3]Fisher Vectorは混合ガウス分布を利用したソフト量子化により,特徴量をエンコードする手法である. 本研究では,128次元のSURF特徴量を1000個ランダムサンプリングし,エンコードした. ガウス分布のクラスタ数は256とした.2 Deep Convolutional Neural Network (DCNN)[4]本研究では,オープンソースであるOverfeat[5]を利用してDCNN特徴を抽出している. Overfeatは,ImageNet Challengeの1000カテゴリでpre-trainingされている. 本研究では,Convolutionalの最後の層のLayer5と,fully-connected層のLayer6とLayer7の出力結果をL2正規化し特徴量として扱う.
3 Support Vector Machine(SVM)識別にはSVM を用いる. IFV,DCNNは高次元なので線形SVM を利用する.
5 実験二十種類のオノマトペを用いて,質感画像データセットの構築,質感画像の認識率の評価を行った1 データセットの構築
表1にデータセットの精度の平均値を示した.
DCNN特徴の結果はFisher vectorと比較するとどのLayerにおいてもよい結果となったが,特にlayer6によるリランキングの精度がよかった. 図2にDCNN特徴のLayer6による20種類のオノマトペ画像データセットの例を示す.
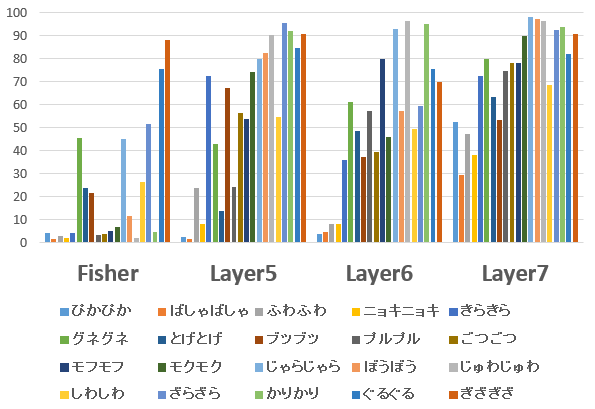
2 認識可能性の評価認識可能性をランダム画像との分離度で評価した. また,評価は5 fold cross varidationで行った. 表2に評価の平均値,図3に各オノマトペの評価結果を示した..
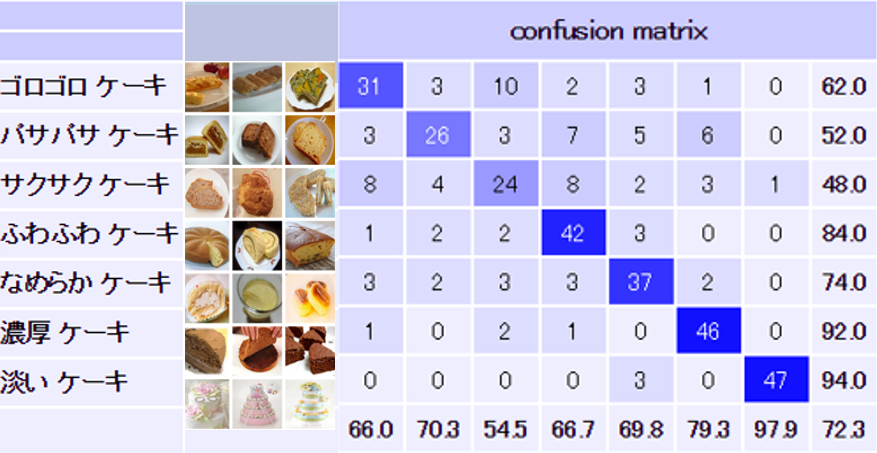
3 名詞+オノマトペの分類オノマトペで収集した画像は特定の物体に偏ることがあり,意味的な認識を行えているか不確かな場合があった. そこで,同一名詞内でのオノマトペマルチクラス分類を行った. 犬,ケーキ,靴,花の四つの名詞で名詞+オノマトペ画像を収集し,同一名詞内でオノマトペマルチクラス分類を行った.1 名詞に対応するオノマトペの決定Webテキスト検索を利用して,名詞のコーパスを作成し,共起頻度でオノマトペを選択した. 今回は共起頻度で得られるオノマトペが少なかったので,形容詞も用いた.2 同一名詞内オノマトペマルチクラス分類図4にケーキにおけるオノマトペマルチクラスの分類結果を示した. マルチクラスの分類率(7クラス)は,72.3%, オノマトペクラスのみの分類率は,61.5%となった.
6 考察オノマトペ画像とランダム画像の分離は,結果がランダムであった場合,0.05%程度になることを考えると,良い精度で分類することができた. しかし,物体認識のバイアスにより,認識が容易になっている可能性があった.そこで,物体認識のバイアスを抑えるために,同一名詞内でマルチクラス分類を行った. 6〜8クラス(300〜400枚)での分類であったことを考慮するとよい精度で分類することができた. 質感の認識に対してDCNN特徴はIFVと比べて有効であることが言える. 7 今後の課題意味的な認識の精度を正しく評価するために,物体認識のバイアスを抑える必要がある. fine-tuningや各レイヤーの学習方法の変更などにより,CNNを質感の認識に最適化することで改善が期待できる.
参考文献
|